
[Technology Newsletter] AI Trust, Risk, and Security Management (TRiSM) (Ep.1)
Trí tuệ nhân tạo (AI) đã được ứng dụng trong gần như mọi khía cạnh của cuộc sống hiện đại, tạo nên sự biến đổi trong các ngành công nghiệp và cách mạng hóa cách chúng ta làm việc cũng như tương tác. Tuy nhiên, sự tiến bộ nhanh chóng này cũng đặt ra những thách thức mới, đặc biệt là về quản lý độ tin cậy, rủi ro và bảo mật.
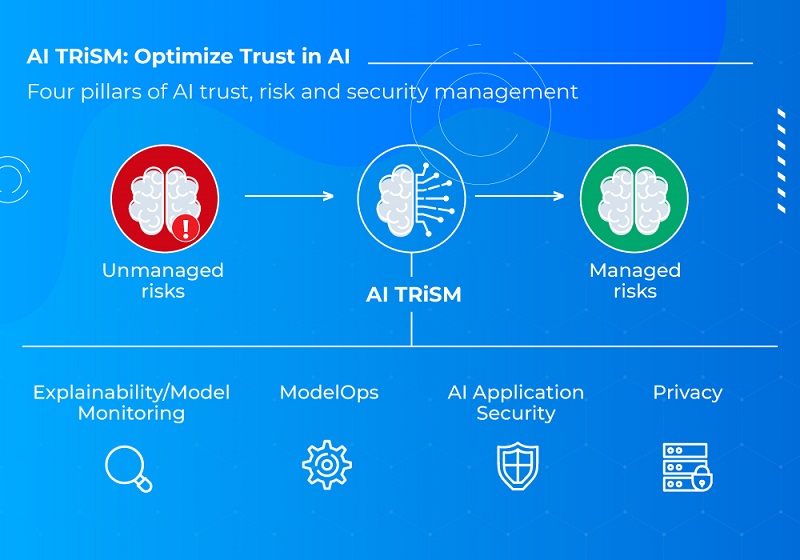
Giới thiệu về AI TRiSM

Gartner - một tập đoàn nghiên cứu và tư vấn công nghệ hàng đầu trên thế giới đã đưa ra báo cáo về 10 xu hướng công nghệ chiến lược hàng đầu mới nhất năm 2024. Báo cáo này nhấn mạnh những đổi mới có thể nhanh chóng thúc đẩy các mục tiêu kinh doanh của doanh nghiệp, đặc biệt quan trọng trong thời đại mà AI phát triển nhanh chóng. Đáng chú ý, trong báo cáo, AI Trust, Risk và Security Management (TRiSM) đứng số 1 trong danh sách, chứng minh sự cần thiết phải giải quyết vấn đề về độ tin cậy, rủi ro và bảo mật trong các mô hình AI.
AI TRiSM là gì?
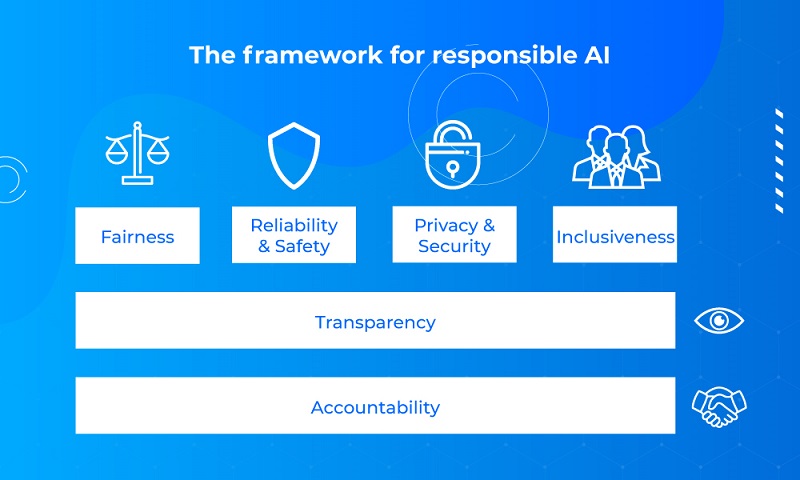
- Sự công bằng (Fairness)
- Độ tin cậy và an toàn (Reliability & Safety)
- Đảm bảo riêng tư và bảo mật (Privacy & Security)
- Sự toàn diện (Inclusiveness)
- Tính minh bạch (Transparency)
- Trách nhiệm giải trình (Accountability)
- Mang lại lợi ích cho xã hội.
- Tránh tạo ra hoặc củng cố những định kiến không công bằng.
- Được xây dựng và kiểm tra để đảm bảo an toàn.
- Chịu trách nhiệm trước con người.
- Tích hợp các nguyên tắc thiết kế về bảo mật.
- Duy trì các tiêu chuẩn cao, sự xuất sắc về mặt khoa học.
- Được sử dụng cho các mục đích phù hợp với những nguyên tắc nêu trên.

Tham khảo thêm về Nguyên tắc AI của Google – Google AI
4. IBM AI Ethics
- Khả năng giải thích (Explainability)
- Sự công bằng (Fairness)
- Sự bền vững (Robustness)
- Tính minh bạch (Transparency)
- Sự riêng tư (Privacy)
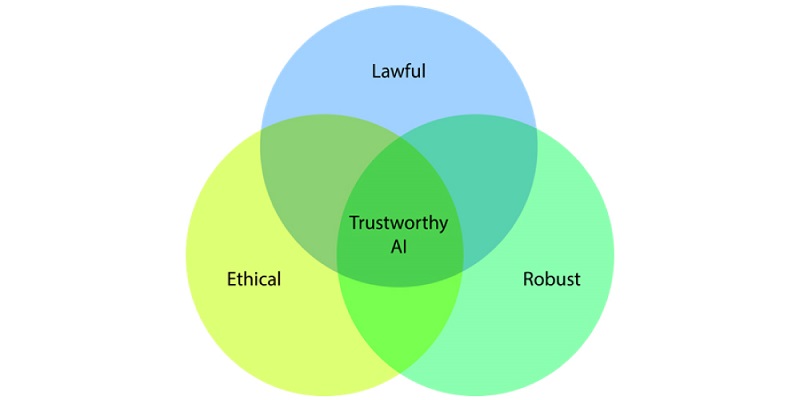
- Hợp pháp (Lawful) - tôn trọng tất cả các luật và quy định hiện hành
- Đạo đức (Ethical) - tôn trọng các nguyên tắc và giá trị đạo đức
- Bền vững (Robust) - cả từ góc độ kỹ thuật đồng thời tính đến môi trường xã hội của nó
Tăng cường Giải thích và Minh bạch (XAI):
Với sự xuất hiện của các quy định mới về AI, như Luật AI của Liên minh Châu Âu (EU – Ethics guidelines for trustworthy AI - mục I.5), nhu cầu về các hệ thống AI có khả năng giải thích ngày càng tăng. Các công cụ Explainable AI (XAI) không chỉ giúp hiểu rõ hơn về cách mà AI đưa ra quyết định mà còn giúp phát hiện và khắc phục các lỗi hoặc thiên vị trong quá trình này.
Hãy tưởng tượng một mô hình AI dự đoán kết quả của bệnh nhân (ứng dụng AI trong lĩnh vực chăm sóc sức khỏe). Để tăng tính minh bạch, quá trình ra quyết định của mô hình được triển khai như sau

Đoạn mã này sử dụng thư viện SHAP để tạo ra lời giải thích cho từng dự đoán, cho phép các bác sĩ hiểu lý do tại sao mô hình lại đưa ra một kết luận cụ thể.
Phát triển và Áp dụng ModelOps:
ModelOps (được hiểu là model operations hoặc model operationalization) giúp quản lý vòng đời của các mô hình AI từ thiết kế, phát triển đến triển khai và bảo trì. Xu hướng này giúp các tổ chức đảm bảo rằng các mô hình AI của họ luôn cập nhật, hiệu quả và có thể mở rộng.
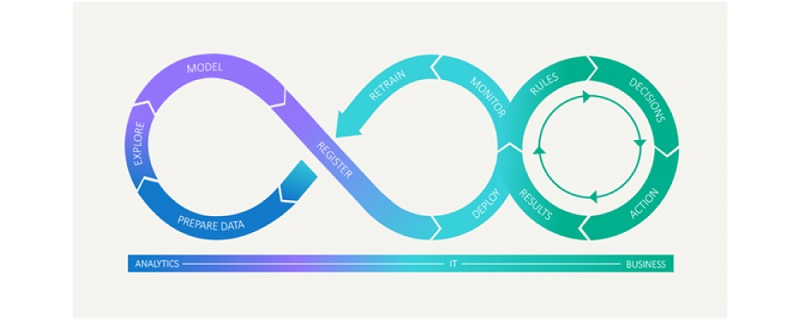
Minh họa vòng đời của ModelOps
Tổng quan về công cụ và công nghệ sử dụng trong ModelOps
- Version control systems (hệ thống kiểm soát phiên bản): Git hoặc các hệ thống khác tương tự, cung cấp khả năng quản lý, theo dõi các phiên bản code của model một cách hiệu quả. Ngoài ra nhằm đảm bảo quy trình làm việc hợp tác, truy xuất nguồn gốc, phân nhánh, hợp nhất hoặc khôi phục các đoạn mã đã triển khai cho model.
- Containerization (container hóa): Tận dụng những containerization platform như Docker, Kubernetes vào quá trình xây dựng model, giúp model và những phụ thuộc đi kèm theo có thể đóng gói, sau đó việc triển khai và thực thi nhất quán trên các môi trường khác nhau, từ giai đoạn phát triển cho đến sản phẩm.
- Continuous integration and deployment (Tích hợp và triển khai liên tục): Những công cụ CI/CD như Jenkins, GitLab CI/CD, CircleCI,… góp phần triển khai tự động hóa quá trình xây dựng, thử nghiệm, triển khai các model một cách liền mạch.
- Model development and experimentation platforms (Nền tảng phát triển và thử nghiệm model): Các nền tảng như Jupyter Notebooks, Google Colab và Databricks cung cấp môi trường cộng tác để phát triển model, thử nghiệm và tạo mẫu.
- Machine learning frameworks and libraries: Các framework machine learning phổ biến như TensorFlow, PyTorch và scikit-learn, cùng với các thư viện liên quan, cung cấp nhiều công cụ khác nhau để phát triển và đào tạo các mô hình machine learning. Các framework này cung cấp các thuật toán, tiện ích xử lý dữ liệu và chức năng đánh giá model.
- Model serving and deployment tools (Công cụ phục vụ và triển khai mô hình): Các công cụ như TensorFlow Serve, TorchServe và MLflow đóng vai trò là cơ sở hạ tầng để triển khai các mô hình đã được đào tạo vào production. Chúng cho phép phân phát các mô hình một cách hiệu quả và có thể mở rộng, xử lý các yêu cầu đồng thời cũng như tạo điều kiện thuận lợi cho việc tạo lập phiên bản và khôi phục model.
- Monitoring and observability tools (Công cụ giám sát và quan sát): Các công cụ giám sát như Prometheus, Grafana và ELK stack (Elasticsearch, Logstash, Kibana) giúp theo dõi hiệu suất và tình trạng của các mô hình đã triển khai. Chúng cung cấp các khả năng đo lường, ghi nhật ký và trực quan hóa theo thời gian thực, cho phép chủ động xác định các điểm bất thường và các vấn đề về hiệu suất.
- Model performance tracking and management platforms (Nền tảng quản lý và theo dõi hiệu suất của model): Các nền tảng như MLflow và TensorBoard hỗ trợ theo dõi và quản lý hiệu suất mô hình. Chúng cho phép ghi lại số liệu, trực quan hóa tiến trình đào tạo, so sánh các phiên bản mô hình và tạo điều kiện cộng tác giữa các thành viên trong nhóm.
- Model explainability and interpretability tools (Các công cụ có thể giải thích và diễn giải model): Các công cụ như thư viện SHAP (SHapley Additive exPlanations), LIME (Local Interpretable Model-agnostic Explanations) và thư viện XAI (Explainable AI) giúp hiểu và diễn giải các dự đoán của model. Chúng cung cấp các kỹ thuật để tạo ra các giải thích, phân tích tầm quan trọng của tính năng và trực quan hóa.
- Automated Machine Learning (AutoML) platforms (Nền tảng tự động hóa machine learning): Các nền tảng AutoML như H2O.ai, DataRobot và Google Cloud AutoML tự động hóa các giai đoạn khác nhau của quy trình phát triển model.
- Model governance and compliance solutions (Giải pháp quản trị và sự tuân thủ của model): Các công cụ và nền tảng như Clarify của OpenAI, IBM Watson OpenScale và Fiddler.ai hỗ trợ quản trị và sự tuân thủ của model. Chúng cho phép giải thích model, đánh giá tính công bằng, phát hiện sai lệch và theo dõi tuân thủ quy định.
Phòng chống tấn công đối kháng:
Khi các cuộc tấn công đối kháng ngày càng tinh vi, việc phát triển các biện pháp phòng chống trở nên cần thiết. Xu hướng này giúp bảo vệ các hệ thống AI khỏi các cuộc tấn công mạng và đảm bảo tính toàn vẹn của dữ liệu.
Sau đây là một đoạn mã trình bày cách có thể tạo ra các hình ảnh đối nghịch để kiểm tra tính bền vững của mô hình nhận dạng hình ảnh. Bằng cách cho mô hình tiếp xúc với các cuộc tấn công như vậy, các nhà phát triển có thể xác định các lỗ hổng và cải thiện tính bảo mật của mô hình.

Phát hiện và giám sát dị thường dữ liệu:

Việc phát hiện các dị thường trong dữ liệu giúp ngăn chặn các lỗi và rủi ro có thể ảnh hưởng đến hiệu suất và độ tin cậy của các mô hình AI. Các công cụ giám sát dữ liệu liên tục và điều chỉnh mô hình theo thời gian là xu hướng quan trọng trong việc duy trì sự chính xác và đáng tin cậy của AI.
Sau đây là một trường hợp sử dụng trong lĩnh vực tài chính - Phát hiện sai lệch trong phê duyệt khoản vay.
Sự thiên vị trong các mô hình AI có thể dẫn đến kết quả không công bằng, đặc biệt là trong các lĩnh vực nhạy cảm như phê duyệt khoản vay. Hãy cùng xem qua đoạn mã triển khai như sau:
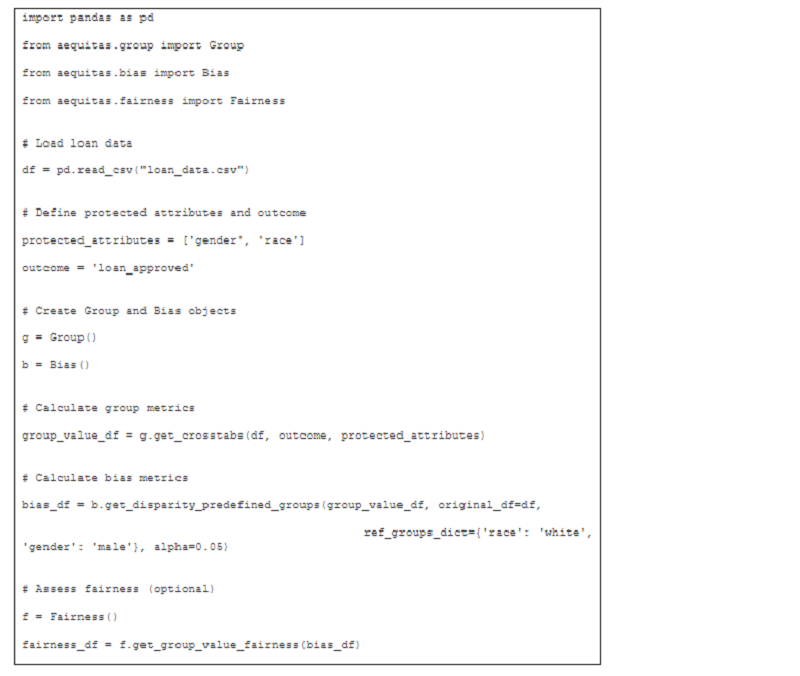
- Tải dữ liệu: Chúng ta tải dữ liệu khoản vay với thông tin về người nộp đơn và trạng thái phê duyệt của họ.
- Xác định các thuộc tính: Chúng ta xác định 'giới tính' và 'chủng tộc' là các thuộc tính được bảo vệ mà chúng tôi muốn kiểm tra xem có thành kiến hay không.
- Thư viện Aequitas: Chúng ta sử dụng thư viện Aequitas để phân tích sai lệch.
- Tính toán số liệu: Chúng ta tính toán số liệu nhóm (ví dụ: tỷ lệ phê duyệt trên mỗi nhóm) và số liệu sai lệch (ví dụ: sự chênh lệch về tỷ lệ phê duyệt giữa các nhóm).
- Đánh giá tính công bằng: Chúng ta có thể đánh giá thêm xem liệu sự chênh lệch quan sát được có đáp ứng các tiêu chí về tính công bằng hay không.
Đầu ra sẽ hiển thị tỷ lệ chấp thuận cho các nhóm nhân khẩu học khác nhau và các biện pháp thống kê về sự chênh lệch. Bằng cách phân tích sự chênh lệch đáng kể có thể chỉ ra sự sai lệch tiềm ẩn trong mô hình.
Bảo vệ dữ liệu và quyền riêng tư:
Trong bối cảnh các quy định về bảo vệ dữ liệu ngày càng nghiêm ngặt, việc bảo vệ quyền riêng tư của người dùng trở thành ưu tiên hàng đầu. Các công nghệ bảo mật dữ liệu tiên tiến và quy trình tuân thủ quy định giúp đảm bảo rằng dữ liệu người dùng được bảo vệ một cách toàn diện.
Chúng ta cùng xem xét những thách thức về quyền riêng tư trong Mô hình Ngôn ngữ Lớn (Large Language Models - LLMs) như GPT-3 and BERT.
LLMs được đào tạo trên các bộ dữ liệu đa dạng thu thập từ internet, bao gồm blog cá nhân, diễn đàn và mạng xã hội, nội dung có bản quyền, khiến chúng dễ học và tái hiện thông tin cá nhân. Hơn nữa, quy mô lớn của các mô hình này làm tăng rủi ro, vì chúng có thể ghi nhớ các điểm dữ liệu từ tài liệu đào tạo của chúng, dẫn đến các vi phạm quyền riêng tư tiềm ẩn.
Từ những thách thức đó, một số kỹ thuật bảo vệ quyền riêng tư được giới thiệu như sau:
Quyền riêng tư vi sai (Differential Privacy – viết tắt: DP)
- DP thêm độ nhiễu vào dữ liệu hoặc quá trình học, đảm bảo việc thêm hoặc bớt một điểm dữ liệu không ảnh hưởng đáng kể đến kết quả phân tích.
- Thực hiện DP trong giai đoạn đào tạo LLM bằng cách sử dụng các thư viện như TensorFlow Privacy hoặc PyTorch Opacus.
Một ví dụ cho việc triển khai DP trong giai đoạn đào tạo LLM bằng cách sử dụng các thư viện như TensorFlow Privacy hoặc PyTorch Opacus.

- Cho phép LLMs được đào tạo trên nhiều thiết bị hoặc máy chủ phân tán mà không cần tập trung dữ liệu.
- Tăng cường quyền riêng tư bằng cách giữ dữ liệu nhạy cảm trên thiết bị của người dùng, chỉ chia sẻ các cập nhật mô hình với máy chủ trung tâm.
- Cho phép thực hiện các phép tính trên dữ liệu đã mã hóa, và trả về kết quả ở dạng mã hóa có thể giải mã nhưng không để tiết lộ bất kỳ thông tin trên dữ liệu thô.
- Áp dụng trong giai đoạn suy luận của LLMs để đảm bảo dữ liệu luôn được mã hóa trong quá trình xử lý.
- Cho phép một nhóm các bên cùng tính toán một hàm trên các đầu vào của họ mà không tiết lộ các đầu vào đó.
- SMPC có thể hỗ trợ đào tạo hoặc suy luận mô hình hợp tác mà không tiết lộ dữ liệu của từng người tham gia.
- Trước khi đào tạo LLMs, dữ liệu có thể được ẩn danh hoặc giả danh để loại bỏ hoặc che giấu các định danh có thể liên kết dữ liệu với cá nhân.
- Giảm thiểu rủi ro vi phạm quyền riêng tư bằng cách đảm bảo rằng mô hình không học cách tái tạo thông tin có thể nhận dạng.
- Tuân thủ các khung pháp lý như GDPR (EU) và CCPA (California) đòi hỏi kế hoạch và thực hiện kỹ lưỡng các biện pháp bảo mật ngay từ đầu của quá trình phát triển mô hình.
- Thường xuyên đánh giá sự ảnh hưởng quyền riêng tư và thể hiện sự minh bạch với các bên liên quan về các thực hành quyền riêng tư được áp dụng.
